I've been working on approximate inference for Bayesian neural networks for quite a while. But when I talk to deep learning people, most of them say "interesting, but I still prefer back-propagation with stochastic gradient descent". Then people in the approximate inference community start to think about how to link SGD to approximate inference, and in this line a very recent paper catched my eyes:
A Variational Analysis of Stochastic Gradient Algorithms
Stephan Mandt, Matt Hoffman, and David Blei, ICML 2016
http://jmlr.org/proceedings/papers/v48/mandt16.pdf
I'm not a big fan of sampling/stochastic dynamics methods (probably because most of the time I test things on neural networks), but I found this paper very enjoyable, and it makes me think I should learn more about this topic. It differs from SGLD and many other MCMC papers in that the authors didn't attempt to recover the exact posterior, but instead they did approximate SVI to keep the computations fast (although the assumptions they made are quite restrictive). There's no painstaking learning rate tuning: the paper also suggests optimal constant learning rate following the guidance of variational inference.
(Figure from the paper's ICML poster)
How does it work? Well, the authors wrote down the continuous dynamics of SGD, made a few assumptions based on CLT, quadratic approximation to the objective function near local optima, then figured out the stationary distribution 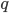 of this process and optimize the learning rate as a hyper-parameter of that . To be precise, let's first write down the objective function of MAP we want to minimize wrt. the model parameters
of this process and optimize the learning rate as a hyper-parameter of that . To be precise, let's first write down the objective function of MAP we want to minimize wrt. the model parameters 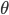 :
: 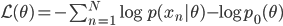 . For convenience the author considered working with
. For convenience the author considered working with 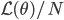 and denote its gradient as
and denote its gradient as 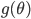 . It's straight-forward to see that now the stochastic gradient
. It's straight-forward to see that now the stochastic gradient 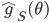 estimated on minibatch
estimated on minibatch 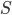 is an unbiased estimate of
is an unbiased estimate of 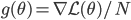 , and from CLT we know that
, and from CLT we know that 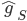 is asymptotically Gaussian distributed. So here the authors make the first assumption:
is asymptotically Gaussian distributed. So here the authors make the first assumption:
(A1) 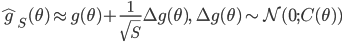
In the following are two more assumptions that when the algorithm gets close to convergence,
(A2) the noise covariance is a constant and can be decomposed, i.e. 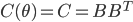 ; (this sounds severe but let's just assume it for simplicity)
; (this sounds severe but let's just assume it for simplicity)
(A3) near the local optimum the loss function  can be well approximated with a quadratic term
can be well approximated with a quadratic term 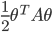 . (easy to derive from Taylor expansion and
. (easy to derive from Taylor expansion and 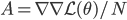 )
)
Based on these assumptions the authors wrote down the continuous time stochastic differential equation of SGD as an Ornstein-Uhlenbeck process:
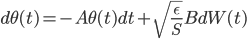
where 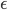 is the learning rate we will optimize later. The OU process has a stationary distribution which is a Gaussian:
is the learning rate we will optimize later. The OU process has a stationary distribution which is a Gaussian: ![q(\theta) \propto \exp \left[-\frac{1}{2} \theta^T \Sigma^{-1} \theta \right]](http://www.yingzhenli.net/home/blog/wp-content/plugins/latex/cache/tex_1dd4e70879ab877ee2b3ed2b2dc7c262.gif) with the variance
with the variance 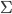 satisfying
satisfying 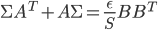 .
.
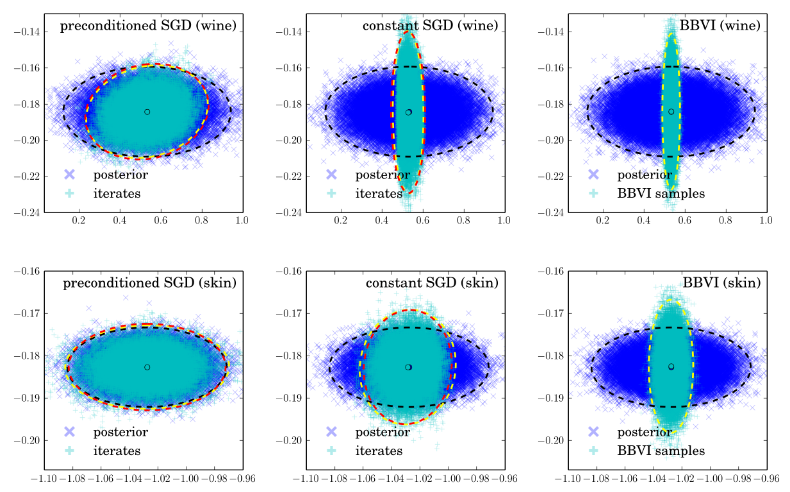
Now comes the main contribution of the paper. What if we use this stationary distribution as an approximation of the true posterior? Note that is a function of matrix 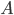 , the mini-batch size , but more importantly, the learning rate . So the authors used variational inference (VI) to minimize
, the mini-batch size , but more importantly, the learning rate . So the authors used variational inference (VI) to minimize ![\mathrm{KL}[q(\theta)||p(\theta|x_1, ..., x_N)]](http://www.yingzhenli.net/home/blog/wp-content/plugins/latex/cache/tex_688b54f4781d9080e5cf384f0b175b64.gif) wrt. , and suggested running constant learning rate SGD with the minimizer
wrt. , and suggested running constant learning rate SGD with the minimizer 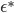 as approximately sampling from the exact posterior. Similar procedure can be done if we use a pre-conditioning matrix
as approximately sampling from the exact posterior. Similar procedure can be done if we use a pre-conditioning matrix 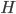 (as a full or diagonal matrix) and they also worked out the optimal solutions for them. I'm not going to run through the maths here but here I just copy the solutions for interests (with
(as a full or diagonal matrix) and they also worked out the optimal solutions for them. I'm not going to run through the maths here but here I just copy the solutions for interests (with 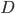 dimensional data):
dimensional data):
(constant SGD) 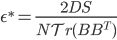
(full pre-conditioned SGD) 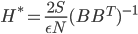
(diagonal) 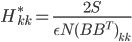
The authors also discussed connections to Stochastic Gradient Fisher Scoring and RMSprop (I think they incorrectly claimed for Adagrad) which looks fun. But let's stop here and talk about what I think about the main results.
First we notice that 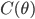 can be viewed as the empirical variance of the gradient
can be viewed as the empirical variance of the gradient 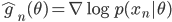 . Now if the model is correct, then approaches to the Fisher information matrix
. Now if the model is correct, then approaches to the Fisher information matrix ![I(\theta) = \mathbb{E}_x[\nabla \log p(x|\theta)^2]](http://www.yingzhenli.net/home/blog/wp-content/plugins/latex/cache/tex_92488f0955aa08b95f4f9dc0ae6297e5.gif) as the number of datapoint
as the number of datapoint 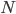 goes to infinity. Then a well known result says we can rewrite the Fisher information matrix as
goes to infinity. Then a well known result says we can rewrite the Fisher information matrix as ![I(\theta) = \mathbb{E}_x[-\nabla \nabla \log p(x|\theta)] = \lim_{N \rightarrow +\infty} \nabla \nabla \mathcal{L}(\theta) / N](http://www.yingzhenli.net/home/blog/wp-content/plugins/latex/cache/tex_eedda9e4535ffba1657000de3726a5e2.gif) . So my first guess is that if we run SGD on large datasets (we usually do) and it converges to a local optimum, then the pre-conditioned SGD with full/diagonal matrix should return very similar approximate posterior distributions to Laplace approximation/mean field VI, respectively. It's pretty easy to show them, just by substituting the optimal
. So my first guess is that if we run SGD on large datasets (we usually do) and it converges to a local optimum, then the pre-conditioned SGD with full/diagonal matrix should return very similar approximate posterior distributions to Laplace approximation/mean field VI, respectively. It's pretty easy to show them, just by substituting the optimal 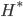 back to the constraints of and notice
back to the constraints of and notice 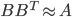 . You can do similar calculations for the constant SGD and get an isotropic Gaussian back with the precision equals to the average value of 's diagonal entries.
. You can do similar calculations for the constant SGD and get an isotropic Gaussian back with the precision equals to the average value of 's diagonal entries.
However most of the time we know the model is wrong. In this case Laplace approximation can possible return terrible results. I think this paper might be useful for those who don't want to directly use traditional approximate inference schemes (in the cost of storing and using more parameters) and still want to get a good posterior approximation. But the performance of the SGD proposals really depend on how you actually estimate the matrix 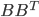 . Also note that case it's considered expensive to evaluate the empirical variance on the whole dataset, and instead people often use running average (see RMSprop for an example). Even if we assume the mini-batch variance is a good approximation, when the samples are hovering around, assumption (A2) doesn't hold apparently. So the next question to ask is: can the popular adaptive learning rate schemes return some kind of approximation to the exact posterior? My experience with RMSprop says that it tends to move around the local optimum, so is it possible to get uncertainty estimates from the trajectory? And how reliable would that be? This sounds very interesting research problems and probably I need to think about it in a bit more detail.
. Also note that case it's considered expensive to evaluate the empirical variance on the whole dataset, and instead people often use running average (see RMSprop for an example). Even if we assume the mini-batch variance is a good approximation, when the samples are hovering around, assumption (A2) doesn't hold apparently. So the next question to ask is: can the popular adaptive learning rate schemes return some kind of approximation to the exact posterior? My experience with RMSprop says that it tends to move around the local optimum, so is it possible to get uncertainty estimates from the trajectory? And how reliable would that be? This sounds very interesting research problems and probably I need to think about it in a bit more detail.
UPDATE 11/08/16
After a happy chat with Stephan (the first author), we agreed that even when the model is wrong, the OU process predicted approximation of full-preconditioning SGD still gives you Laplace approximation (although practical simulation might disagree since the assumptions doesn't hold). My guess for the other two cases depends on that the data comes from the model.