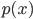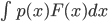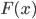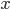Update: another major update of this monograph document is in. Some small updates are still in schedule to finish before the end of 2020.
Current version (Dec 2020) (pdf)
Next major update will be on applications of approximate inference in machine learning.
Read the following explainers before you decide to delve in this subject ?
What is approximate inference? more
Why I should care about it? more
Now you might ask: why I should care about this approximate integral in the first place? Couldn't we just forget about integrals and do point estimations instead? Or couldn't we just use models that can do exact inference (e.g. stacking invertible transformations, auto-regressive models, sum-product networks)? Well for the first question it's more like a debate between Frequentist and Bayesian which I don't think I should say too much about it here. But I shall emphasize that integration is almost everywhere in probability and statistics, say calculating expectations and computing marginal distributions. For the second question, those models are usually more computationally demanding (both in time and memory), which is exactly the point for not using them and do approximate inference instead if you don't have that much computational resource. Approximate inference only makes sense when you do have computational constraints, and the way you do approximate inference also depends on how much precision you want and computational resource you have.
What this list is about? more
There are mainly two ways to do approximate inference: directly approximating the integral you want, or, finding an accurate approximation 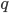 to the target distribution
to the target distribution 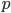 and using it for integration later. The first approach is mainly dominated by sampling methods (and maybe adding student models to distill it) and quadrature. The second one, sometimes referred as the indirect approach, will be the focus of this list.
and using it for integration later. The first approach is mainly dominated by sampling methods (and maybe adding student models to distill it) and quadrature. The second one, sometimes referred as the indirect approach, will be the focus of this list.