
Working papers
Wuhao Chen, Zijing Ou and Yingzhen Li. Neural Flow Samplers with Shortcut Models. In submission. 2025.
Harrison Zhu, Adam Howes, Owen van Eer, Maxime Richard, Yingzhen Li, Dino Sejdinovic and Seth Flaxman. Aggregated Gaussian Processes with Multiresolution Earth Observation Covariates. 2022.
Wenbo Gong and Yingzhen Li. Interpreting Diffusion Score Matching using Normalizing Flow. ICML 2021 INNF+ workshop.
Refereed conference papers
Zijing Ou, Ruixiang Zhang and Yingzhen Li. Discrete Neural Flow Samplers with Locally Equivariant Transformer. Neural Information Processing Systems (NeurIPS), 2025.
I. Shavindra Jayasekera, Jacob Si, Filippo Valdettaro, Wenlong Chen, Aldo A. Faisal and Yingzhen Li. Variational Uncertainty Decomposition for In-Context Learning. Neural Information Processing Systems (NeurIPS), 2025.
Yohan Jung, Hyungi Lee, Wenlong Chen, Thomas Möllenhoff, Yingzhen Li, Juho Lee, Mohammad Emtiyaz Khan. Compact Memory for Continual Logistic Regression. Neural Information Processing Systems (NeurIPS), 2025.
Naoki Kiyohara, Edward Johns and Yingzhen Li. Neural Stochastic Flows: Solver-Free Modelling and Inference for SDE Solutions. Neural Information Processing Systems (NeurIPS), 2025.
Wenlong Chen*, Naoki Kiyohara*, Harrison Bo Hua Zhu*, Jacob Curran-Sebastian, Samir Bhatt and Yingzhen Li. Recurrent Memory for Online Interdomain Gaussian Processes. Neural Information Processing Systems (NeurIPS), 2025.
Xinzhe Luo, Yingzhen Li and Chen Qin. Unsupervised Accelerated MRI Reconstruction via Ground-Truth-Free Flow Matching. Information Processing in Medical Imaging (IPMI), 2025. (oral)
Manduchi et al. On the Challenges and Opportunities in Generative AI. Transactions on Machine Learning Research (TMLR), 2025.
Carles Balsells Rodas, Xavier Sumba, Tanmayee Narendra, Ruibo Tu, Gabriele Schweikert, Hedvig Kjellstrom and Yingzhen Li. Causal Discovery from Conditionally Stationary Time Series. International Conference on Machine Learning (ICML), 2025.
Wenlong Chen, Bolian Li, Ruqi Zhang and Yingzhen Li. Bayesian Computation in Deep Learning. Handbook of Markov Chain Monte Carlo, 2nd Edition (in press, expected 2025/26, refereed chapter)
Zijing Ou, Mingtian Zhang, Andi Zhang, Tim Z. Xiao, Yingzhen Li and David Barber. Improving Probabilistic Diffusion Models With Optimal Diagonal Covariance Matching. International Conference on Learning Representations (ICLR), 2025. (oral, 1.5%)
Tobias Schröder, Zijing Ou, Yingzhen Li and Andrew Duncan. Energy-Based Modelling for Discrete and Mixed Data via Heat Equations on Structured Spaces. Neural Information Processing Systems (NeurIPS), 2024.
Carles Balsells-Rodas, Yixin Wang and Yingzhen Li. On the Identifiability of Switching Dynamical Systems. International Conference on Machine Learning (ICML), 2024.
Papamakou et al. Position: Bayesian Deep Learning is Needed in the Age of Large-Scale AI. International Conference on Machine Learning (ICML), 2024.
Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Mark A. Hasegawa-Johnson, Yingzhen Li and Chang D. Yoo. C-TPT: Calibrated Test-Time Prompt Tuning for Vision-Language Models via Text Feature Dispersion. International Conference on Learning Representations (ICLR), 2024.
Tobias Schröder, Zijing Ou, Jen Ning Lim, Yingzhen Li, Sebastian Vollmer and Andrew Duncan. Energy Discrepancies: A Score-Independent Loss for Energy-Based Models. Neural Information Processing Systems (NeurIPS), 2023.
Harrison Zhu, Carles Balsells Rodas and Yingzhen Li. Markovian Gaussian Process Variational Autoencoders. International Conference on Machine Learning (ICML), 2023.
Wenlong Chen and Yingzhen Li. Calibrating Transformers via Sparse Gaussian Processes. International Conference on Learning Representations (ICLR), 2023.
Hee Suk Yoon, Joshua Tian Jin Tee, Gwangsu Kim, Eunseop Yoon, Sunjae Yoon, Yingzhen Li and Chang D. Yoo. ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure. International Conference on Learning Representations (ICLR), 2023.
Ryutaro Tanno, Melanie F. Pradier, Aditya Nori and Yingzhen Li. Repairing Neural Networks by Leaving the Right Past Behind. Neural Processing Information Systems (NeurIPS), 2022.
Yanzhi Chen, Weihao Sun, Yingzhen Li and Adrian Weller. Scalable Infomin Learning. Neural Processing Information Systems (NeurIPS), 2022.
Zijing Ou, Tingyang Xu, Qinliang Su, Yingzhen Li, Peilin Zhao and Yatao Bian. Learning Set Functions Under the Optimal Subset Oracle via Equivariant Variational Inference. Neural Processing Information Systems (NeurIPS), 2022.
Hippolyt Ritter, Martin Kukla, Cheng Zhang and Yingzhen Li. Sparse Uncertainty Representation in Deep Learning with Inducing Weights. Neural Processing Information Systems (NeurIPS), 2021.
Thomas Henn, Yasukazu Sakamoto, Clément Jacquet, Shunsuke Yoshizawa, Masamichi Andou, Stephen Tchen, Ryosuke Saga, Hiroyuki Ishihara, Katsuhiko Shimizu, Yingzhen Li and Ryutaro Tanno. A Principled Approach to Failure Analysis and Model Repairment: Demonstration in Medical Imaging. International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), 2021.
Wenbo Gong, Kaibo Zhang, Yingzhen Li and José Miguel Hernández-Lobato. Active Slices for Slided Stein Discrepancy. International Conference on Machine Learning (ICML), 2021
Wenbo Gong, Yingzhen Li and José Miguel Hernández-Lobato. Sliced Kernelized Stein Discrepancy. International Conference on Learning Representations (ICLR), 2021.
Ruqi Zhang, Yingzhen Li, Chris De Sa, Sam Devlin and Cheng Zhang. Meta-Learning for Variational Inference. International Conference on Artificial Intelligence and Statistics (AISTATS), 2021.
Yi Zhu, Ehsan Shareghi, Yingzhen Li, Roi Reichart and Anna Korhonen. Combining Deep Generative Models and Multi-lingual Pretraining for Semi-supervised Document Classification. European Chapter of the Association for Computational Linguistics (EACL), 2021.
Andrew Y. K. Foong*, David R. Burt*, Yingzhen Li and Richard E. Turner. On the Expressiveness of Approximate Inference in Bayesian Neural Networks. Neural Processing Information Systems (NeurIPS), 2020.
Cheng Zhang, Kun Zhang and Yingzhen Li. A Causal View on Robustness of Neural Networks. Neural Processing Information Systems (NeurIPS), 2020.
Maximilian Igl, Kamil Ciosek, Yingzhen Li, Sebastian Tschiatschek, Cheng Zhang, Sam Devlin and Katja Hofmann. Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck. Neural Processing Information Systems (NeurIPS), 2019.
Ehsan Shareghi, Yingzhen Li, Yi Zhu, Roi Reichart and Anna Korhonen. Bayesian Learning for Neural Dependency Parsing. NAACL-HLT 2019.
Chao Ma, Yingzhen Li and José Miguel Hernández-Lobato. Variational Implicit Processes. International Conference on Machine Learning (ICML), 2019. code
Yingzhen Li, John Bradshaw and Yash Sharma. Are Generative Classifiers More Robust to Adversarial Attacks? International Conference on Machine Learning (ICML), 2019. code cartoon

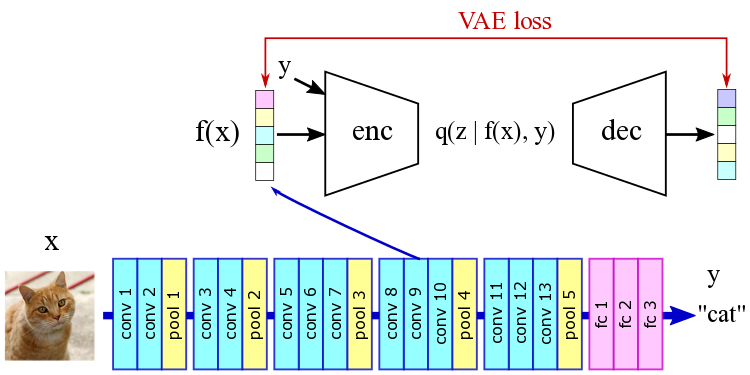
Wenbo Gong*, Yingzhen Li* and José Miguel Hernández-Lobato. Meta-Learning for Stochastic Gradient MCMC. International Conference on Learning Representations (ICLR), 2019. code cartoon


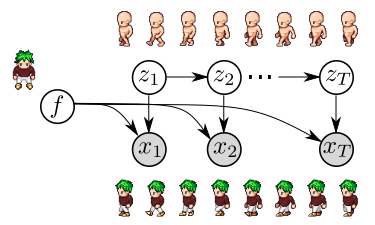
Yingzhen Li and Stephan Mandt. Disentangled Sequential Autoencoder. International Conference on Machine Learning (ICML), 2018. sprites data architecture cartoon
Cuong V. Nguyen, Yingzhen Li, Thang D. Bui and Richard E. Turner. Variational Continual Learning. International Conference on Learning Representations (ICLR), 2018. code cartoon

Yingzhen Li and Richard E. Turner. Gradient Estimators for Implicit Models. International Conference on Learning Representations (ICLR), 2018. code cartoon
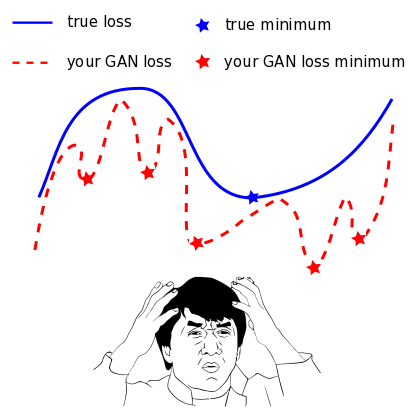
Yingzhen Li and Yarin Gal. Dropout Inference in Bayesian Neural Networks with Alpha-divergences. International Conference on Machine Learning (ICML), 2017. code cartoon

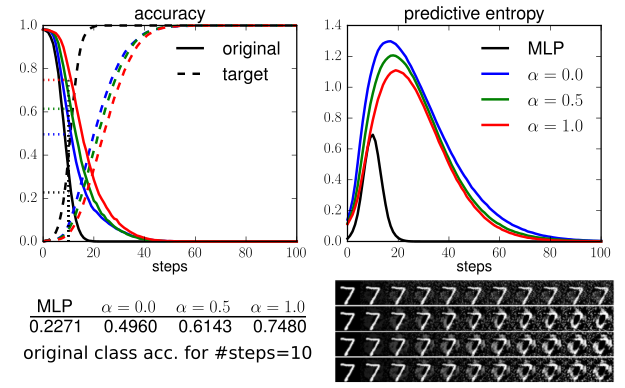
Yingzhen Li and Richard E. Turner. Rényi Divergence Variational Inference. Neural Processing Information Systems (NIPS), 2016. code cartoon
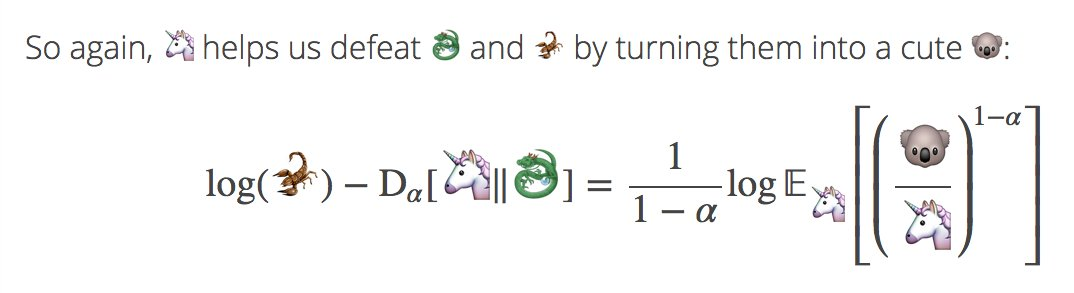

José Miguel Hernández-Lobato*, Yingzhen Li*, Mark Rowland, Daniel Hernández-Lobato, Thang Bui and Richard E. Turner. Black-box α-divergence Minimization. International Conference on Machine Learning (ICML), 2016. code cartoon
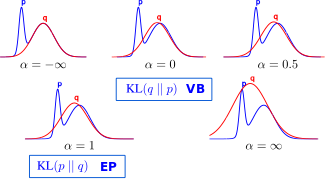
Thang Bui, Daniel Hernández-Lobato, José Miguel Hernández-Lobato, Yingzhen Li and Richard E. Turner. Deep Gaussian Processes for Regression using Approximate Expectation Propagation. International Conference on Machine Learning (ICML), 2016. code cartoon
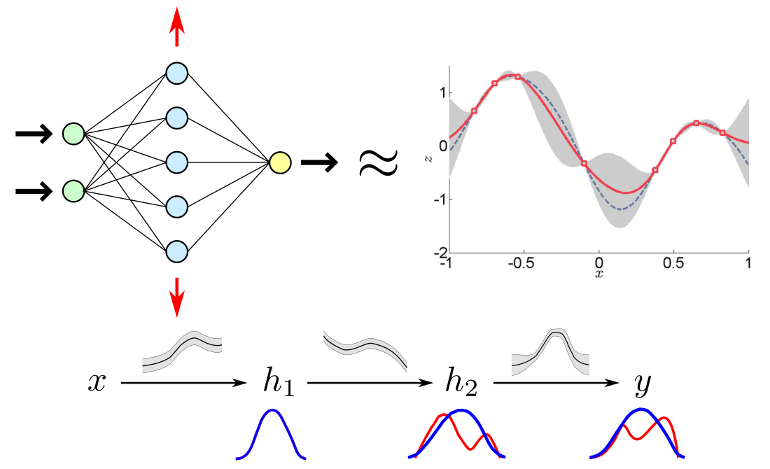
Yingzhen Li, Jose Miguel Hernandez-Lobato and Richard E. Turner. Stochastic Expectation Propagation. Neural Processing Information Systems (NIPS), 2015 (spotlight, 4.5%). demo cartoon
Workshop Preprints
Sebastian Lunz, Yingzhen Li, Andrew Fitzgibbon and Nate Kushman. Inverse Graphics GAN: Learning to Generate 3D Shapes from Unstructured 2D Data. NeurIPS 2020 workshop on Differentiable vision, graphics, and physics applied to machine learning (DiffCVGP), 2020.
Chaochao Lu, Richard E. Turner, Yingzhen Li and Nate Kushman. Interpreting Spatially Infinite Generative Models. ICML 2020 Workshop on Human Interpretability in Machine Learning (WHI), 2020.
Andrew Y.K. Foong, Yingzhen Li, José Miguel Hernández-Lobato and Richard E. Turner. "In-Between" Uncertainty for Bayesian Neural Networks. ICML 2019 workshop on Uncertainty & Robustness in Deep Learning (oral)
Yingzhen Li. Approximate Gradient Descent for Training Implicit Generative Models. NIPS 2017 Bayesian Deep Learning workshop. 2017.
Yingzhen Li, Richard E. Turner and Qiang Liu. Approximate Inference with Amortised MCMC. ICML 2017 Workshop on Implicit Generative Models. 2017. cartoon

Yingzhen Li and Qiang Liu. Wild Variational Approximations. preprint presented in NIPS Advances in approximate inference, 2016. cartoon

Yingzhen Li and Richard E. Turner. A Unifying Approximate Inference Framework from Variational Free Energy Relaxation. NIPS Advances in approximate inference workshop, 2016
Daniel Hernández-Lobato, José Miguel Hernández-Lobato, Yingzhen Li, Thang Bui and Richard E. Turner. Stochastic Expectation Propagation for Large Scale Gaussian Process Classification. NIPS Advances in approximate inference workshop (contributed talk), 2015
Yingzhen Li and Ye Zhang. Generating ordered list of Recommended Items: a Hybrid Recommender System of Microblog. 2012
Thesis
Approximate Inference: New Visions. PhD in Engineering, University of Cambridge, June 2018.
Compressed Sensing and Related Learning Problems. B.S. in Mathematics, Sun Yat-sen University, May 2013. (Best B.S. Thesis Award). [slides]